Todo lo que deberías saber sobre Amazon S3 y Glacier
Amazon S3 es almacenamiento a nivel de objeto, lo que significa que si desea cambiar una parte de un archivo, debe realizar el cambio y luego volver a cargar todo el archivo modificado. Los objetos individuales no pueden ser mayores de 5 TB; sin embargo, Amazon S3 te permite almacenar tantos datos como desee.
De manera predeterminada, los datos en Amazon S3 se almacenan de forma redundante en múltiples instalaciones y múltiples dispositivos en cada instalación. Se puede acceder a Amazon S3 a través de la consola de administración de AWS basada en la web, mediante programación a través de API y SDK, o con soluciones de terceros (que usan API / SDK).
Amazon S3 incluye una nueva opción por defecto llamada «Notificaciones de eventos» que te permitira configurar notificaciones automáticas cuando ocurren ciertos eventos, como un objeto cargado o eliminado de un segmento específico. Esas notificaciones se pueden enviar a tu cuenta de correo, o incluso se pueden usar para desencadenar otros procesos, como los scripts de AWS Lambda.
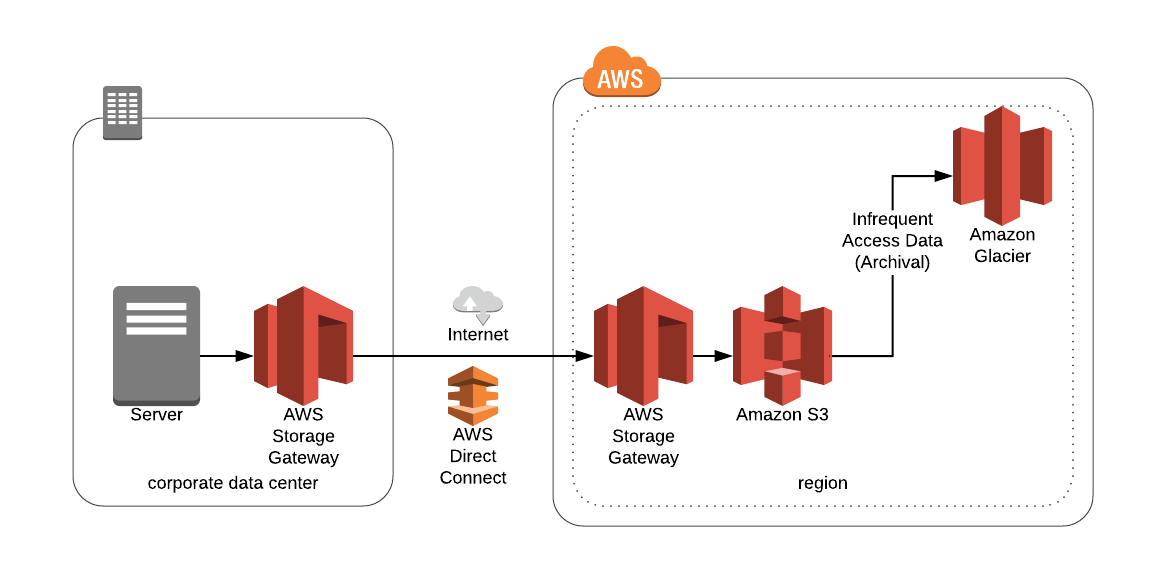
También hay una nueva característica de S3, llamada Amazon S3 Analytics, la cual identifica automáticamente la política del ciclo de vida óptimo para hacer la transición del almacenamiento al que se accede con menos frecuencia a otra capa de almacenamiento dentro de S3 mas barata llamada S3 IA de las siglas en ingles Infrequent Access o acceso infrecuente. Puedes configurar una política de análisis de clase de almacenamiento en un cubo completo, un prefijo o una etiqueta de objeto.
Conceptos simples en Amazon S3
Para obtener el máximo rendimiento de Amazon S3, debes comprender algunos conceptos simples en S3. Primero, Amazon S3 almacena datos dentro de «cubos». Estos cubos deben tener un nombre exclusivo en todo Amazon S3. Los cubos son contenedores lógicos para los archivos que vayamos a subir. Puedes tener uno o más cubos en tu cuenta gratuita de AWS.
Para cada cubo, puedes controlar el acceso, es decir, puedes controlar quién puede crear, eliminar y enumerar objetos o archivos dentro del cubo. También puedes ver los registros de acceso para el cubo y sus objetos, y elegir la región geográfica que mas te convenga donde Amazon S3 almacenará los archivos. La URL de un cubo está totalmente estructurada, con el código de región primero, seguido de amazonaws.com, y por ultimo seguido del nombre del cubo.
Recuerda que Amazon S3 se refiere a los archivos como «objetos». Una vez que tienes un cubo, puedes almacenar cualquier cantidad de objetos dentro de él. Un objeto se compone de datos y cualquier metadato que describa ese archivo. Para almacenar un objeto en Amazon S3, debes de subir el archivo que quieras en un cubo. Cuando subes un archivo, puedes establecer permisos en los datos, así como en cualquier metadato.
Costes de Amazon S3 y opciones
Los costos específicos pueden variar según la región y las solicitudes específicas realizadas. Como regla general, solo pagara por las transferencias que cruzan los límites de su región, lo que significa que no paga las transferencias a las ubicaciones de borde de Amazon CloudFront dentro de esa misma región.
Para almacenar datos en S3, amazon proporciona la opción de Amazon S3 Standard. Sin embargo hay otra opción en S3 llamada Amazon S3 estándar Amazon IA de las siglas en ingles Acceso infrecuente como dijimos anterior mente. Amazon S3 Standard – IA ofrece todos los beneficios de Amazon S3, incluida su durabilidad, disponibilidad y seguridad; pero simplemente se ejecuta en un modelo de costos diferente para proporcionar soluciones para almacenar datos a los que se accede con poca frecuencia, como las imágenes digitales más antiguas de un usuario o archivos de registro antiguos.
Amazon Glacier
Amazon Glacier es un servicio de archivo de datos especialmente diseñado para las copias de seguridad o para aquellos datos que no se necesiten acceder constantemente o inmediatamente.
El archivo de datos en Amazon Glacier significa que aunque puede almacenar sus datos a un costo extremadamente bajo (incluso en comparación con Amazon S3), no puede recuperar sus datos inmediatamente cuando lo desee. Los datos almacenados en Amazon Glacier tardan varias horas en recuperarse, por lo que es ideal para archivar.
Hay tres opciones para recuperar datos con diferentes tiempos de acceso y costo: recuperaciones aceleradas, estándar y masivas, de la siguiente manera:
– Las recuperaciones aceleradas generalmente están disponibles dentro de 1 a 5 minutos.
– Las recuperaciones estándar generalmente se completan dentro de 3 a 5 horas.
– Las recuperaciones a granel generalmente se completan dentro de 5 a 12 horas. (AWS)
Los datos se almacenan en Amazon Glacier en «archivos». Un archivo puede ser cualquier información, como una foto, video o documento. Puede cargar un solo archivo como un archivo o agregar múltiples archivos en un archivo TAR o ZIP y cargarlo como un archivo.
Un solo archivo puede ser tan grande como 40 terabytes. Puede almacenar una cantidad ilimitada de archivos y una cantidad ilimitada de datos en Amazon Glacier. A cada archivo se le asigna una ID de archivo única en el momento de la creación, y el contenido del archivo es inmutable, lo que significa que después de que se crea un archivo, no se puede actualizar.
Las bóvedas (o vaults en ingles) te permitirán organizar tus archivos y establecer políticas de acceso y políticas de notificación. Puedes optar por que se te envíen notificaciones a ti vía correo o a tu aplicación cada vez que se realicen determinados trabajos de Amazon Glacier. Los mensajes de notificación son enviados por el Servicio de notificaciones simples de Amazon (SNS).
Especifique el tema de Amazon SNS que se utilizará para las notificaciones de finalización del trabajo utilizando el Nombre del recurso de Amazon (ARN) del tema. A continuación, selecciona qué tipos de trabajos de Amazon Glacier pueden activar el envío de una notificación al finalizar el trabajo. Las aplicaciones o los usuarios que se suscriben al tema de Amazon SNS reciben un mensaje de notificación cuando finaliza una tarea del tipo que selecciona.
Hay tres opciones para recuperar datos con diferentes tiempos de acceso y costo: 1 es la recuperaciones aceleradas, 2 es el estándar y el tercero es la opción masiva. Las recuperaciones aceleradas generalmente están disponibles dentro de 1 a 5 minutos. Las recuperaciones estándar generalmente se completan dentro de 3 a 5 horas. Las recuperaciones masivas generalmente se completan dentro de 5 a 12 horas.
Políticas de ciclo de vida en S3
Es muy aconsejable que automatices el ciclo de vida de tus datos almacenados en Amazon S3. Al usar políticas de ciclo de vida, puedes hacer que los datos se reciclen a intervalos regulares entre los tres diferentes tipos de almacenamiento de Amazon S3. Esto reduce el costo general, ya que estarás pagando menos por los datos pues con el tiempo ciertos tipos de datos se vuelven menos importantes.
Además de poder establecer reglas de ciclo de vida por objeto, también puedes establecer reglas de ciclo de vida por cubo.
Gracias por leer nuestro blog, participar y compartir.